GPU Memory Limits for BERT
Code♯
This example is derived from GPU Benchmarks for Fine-Tuning BERT [1], which focus on the choice of training batch size. We will use the Anaconda Python installed on Picotte to run this example on GPU.
Python script♯
The Python script is a file named gpu_memory_limit_parameter_search.py It runs many different values of batch size and appends the result into a table. We use the information collected from the table to analyze how the training batch size affects the memory usage.
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
"""GPU Memory Limit Parameter Search.ipynb
Automatically generated by Colaboratory.
Original file is located at
https://colab.research.google.com/drive/15OdPZPVx9OFGK_4eRp8PLOt2yb3Ma5dX
# Find GPU Memory Limits for BERT
By Chris McCormick
This is the Notebook used to gather experimental results for the parameters plot in [GPU Benchmarks for Fine-Tuning BERT.ipynb](https://colab.research.google.com/drive/1Gzm0mBTWQLtI5q8azxwudmZGBWyiq6II#scrollTo=K2He8biUzcij&uniqifier=1)
Here's the quick overview of the experiment:
1. Load BERT-base onto the GPU
2. Create a Tensor with the parameters you want:
* Number of rows is batch size.
* Number of columns is sequence length.
3. Train on the random data for 3 steps.
4. Record the peak GPU memory usage.
* If training fails due to "out-of-memory", record the memory used as -1.
I've stored the results from all of my runs in a `.csv` file on Google Drive.
## S1. Setup
### 1.1. Connect to GPU
"""
import torch
# Tell PyTorch to use the GPU.
device = torch.device("cuda")
print('There are %d GPU(s) available.' % torch.cuda.device_count())
# Look up what kind of GPU we're given.
gpu_name = torch.cuda.get_device_name(0)
print('We will use the GPU:', gpu_name)
"""### 1.2. Install `transformers`
Next, let's install the [transformers](https://github.com/huggingface/transformers) package from Hugging Face which will give us a pytorch interface for working with BERT.
"""
import transformers
"""### 1.3. `check_gpu_mem`
Function to measure GPU memory useage.
"""
import os
import pandas as pd
import csv
def check_gpu_mem():
'''
Uses Nvidia's SMI tool to check the current GPU memory usage.
'''
# Run the command line tool and get the results.
buf = os.popen('nvidia-smi --query-gpu=memory.total,memory.used --format=csv')
# Use csv module to read and parse the result.
reader = csv.reader(buf, delimiter=',')
# Use a pandas table just for nice formatting.
df = pd.DataFrame(reader)
# Use the first row as the column headers.
new_header = df.iloc[0] #grab the first row for the header
df = df[1:] #take the data less the header row
df.columns = new_header #set the header row as the df header
# Display the formatted table.
#display(df)
return df
"""Let's run the function so you can see the output."""
df = check_gpu_mem()
df
"""**NOTE!** - The `first_time` flag is set the first time this Notebook is run. On subsequent runs (within the same runtime), you should start from 2.1."""
# Flag used to determine whether to create a new table or append to existing.
first_time = True
"""## S2. Run Experiment
### 2.1. Specify Parameters (Re-Run From Here)
Set the key parameters and timestamp the experiment.
"""
import time
from datetime import datetime
# The dataset is pre-tokenized, so this only specifies which copy of the dataset
# to fetch.
max_len = 240
batch_size = 0
while (batch_size < 100):
# Record when we started.
timestamp = datetime.fromtimestamp(time.time()).strftime('%Y-%m-%d %H:%M:%S')
# All parameters and results are placed in a table at the very end of the
# notebook.
from transformers import BertForSequenceClassification, AdamW, BertConfig
# Load BertForSequenceClassification, the pretrained BERT model with a single
# linear classification layer on top.
model = BertForSequenceClassification.from_pretrained(
"bert-base-uncased", # Use the 12-layer BERT model, with an uncased vocab.
num_labels = 20, # For our 20 newsgroups!
output_attentions = False, # Whether the model returns attentions weights.
output_hidden_states = False, # Whether the model returns all hidden-states.
)
# Tell pytorch to run this model on the GPU.
desc = model.cuda()
check_gpu_mem()
"""### 2.2. Random Data
Generate some random data that looks like BERT tokens.
"""
import torch
# Create the bogus input batch.
x = torch.randint(low=0, high=100, size=(batch_size, max_len))
# Assign random labels (0 or 1)
labels = torch.randint(low=0, high=1, size=(batch_size, 1))
print('x: ', x.size())
print('labels:', labels.size())
# Copy to the GPU
x = x.to(device)
labels = labels.to(device)
"""### 2.3. Forward & Backward Training Pass
Run the fake data through the model, and perform the gradient calculation, just to see the memory usage.
I did this for three steps simply because, in my experience, the GPU doesn't seem to hit its peak memory usage until after the third step.
"""
# Use a flag to capture whether the experiment either succeeds or runs out of
# memory.
success = False
# It seems like the peak memory use isn't hit until after a few steps, so run
# this through three times.
for i in range(0, 3):
# Put the model into training mode. Don't be mislead--the call to
# `train` just changes the *mode*, it doesn't *perform* the training.
# `dropout` and `batchnorm` layers behave differently during training
# vs. test (source: https://stackoverflow.com/questions/51433378/what-does-model-train-do-in-pytorch)
model.train()
df = check_gpu_mem()
print(' Before forward-pass: {:}'.format(df.iloc[0, 1]))
# Always clear any previously calculated gradients before performing a
# backward pass. PyTorch doesn't do this automatically because
# accumulating the gradients is "convenient while training RNNs".
# (source: https://stackoverflow.com/questions/48001598/why-do-we-need-to-call-zero-grad-in-pytorch)
model.zero_grad()
# Perform a forward pass (evaluate the model on this training batch).
# The documentation for this `model` function is here:
# https://huggingface.co/transformers/v2.2.0/model_doc/bert.html#transformers.BertForSequenceClassification
# It returns different numbers of parameters depending on what arguments
# arge given and what flags are set. For our useage here, it returns
# the loss (because we provided labels) and the "logits"--the model
# outputs prior to activation.
loss, logits = model(x,
token_type_ids=None,
labels=labels)
# Report GPU memory use for the first couple steps.
df = check_gpu_mem()
print(' After forward-pass: {:}'.format(df.iloc[0, 1]))
# Perform a backward pass to calculate the gradients.
loss.backward()
# Report GPU memory use for the first couple steps.
df = check_gpu_mem()
print(' After gradient calculation: {:}'.format(df.iloc[0, 1]))
# If we made it here, we didn't run out of memory. Success!
success = True
"""### 2.4. Record Results
Record all of the parameters and results from this experiment.
After putting these into a table row with pandas below, I've been copying them over to a `.csv` file.
"""
# Record the peak memory use and the total available.
# Record the memory usage.
if success:
mem_use = int(df.iloc[0, 1][:-4])
# If it ran out of memory, use the value -1.
else:
mem_use = -1
# Total memory this GPU.
mem_total = int(df.iloc[0, 0][:-4])
new_row = {'timestamp': timestamp, 'batch_size': batch_size, 'max_len': max_len, 'gpu': gpu_name, 'mem_use': mem_use, 'mem_total': mem_total }
# If this is the first experiment performed within this runtime, then the table
# doesn't exist yet.
if first_time:
# Create the table.
df_res = pd.DataFrame(data=[new_row])
first_time = False
else:
# Append to the table.
df_res = df_res.append(new_row, ignore_index=True)
# Display the accumulated results.
df_res
# Dump the table to CSV and I'll manually copy it over to my aggregated results
# file.
print("TABLE OF RESULT:\n")
print(df_res.to_csv())
batch_size = batch_size + 20
"""## End"""
Job script♯
The job script is a file named bert.sh, in the same directory as gpu_memory_limit_parameter_search.py:
#!/bin/bash
#SBATCH -p gpu
#SBATCH --gres=gpu:1
#SBATCH --time=01:00:00
#SBATCH --mem-per-gpu=48GB
module load python/anaconda3
. ~/.bashrc
conda activate pytorch
python3 gpu_memory_limit_parameter_search.py
Job submission♯
Submit the job script:
[juser@picotte001 ~]$ sbatch bert.sh
Output♯
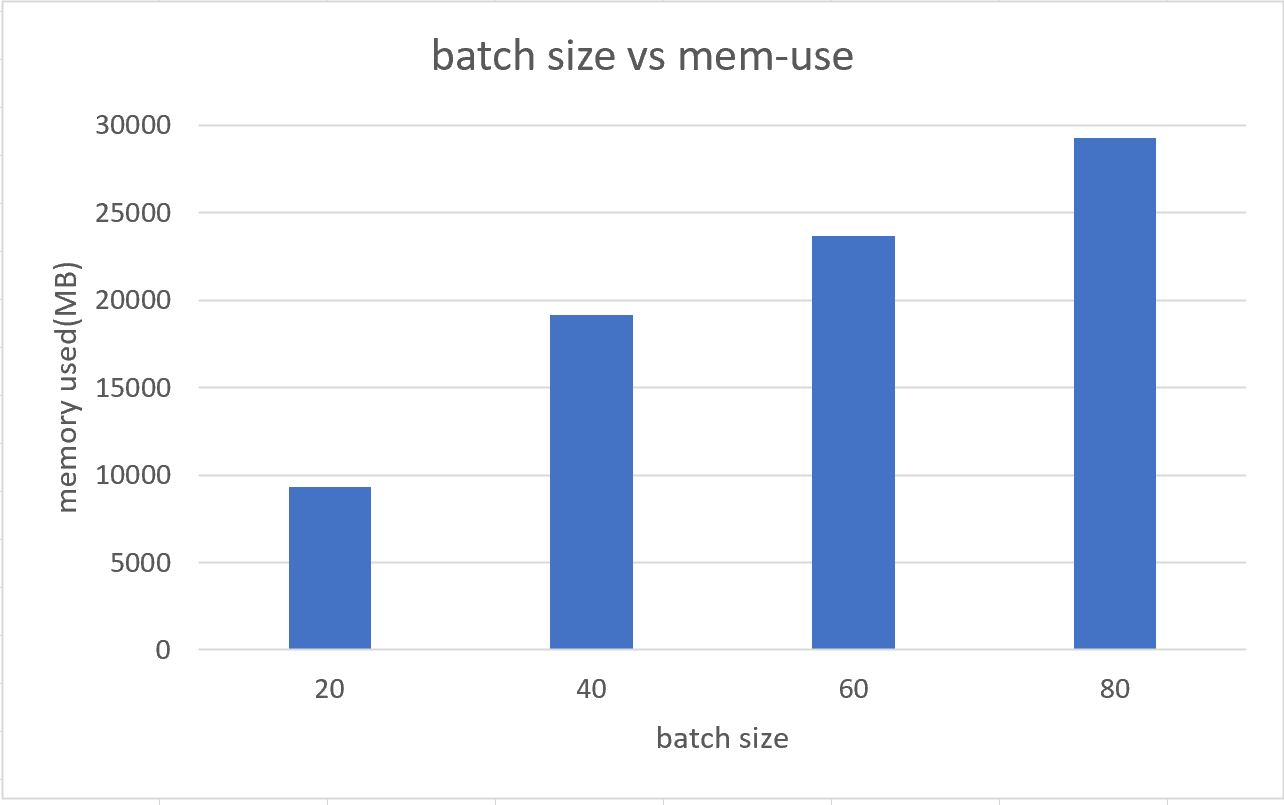
With the GPU: Tesla V100-SXM2-32GB, the bigger the value of training batch size, the bigger the amount of memory used.
When the batch size reaches 100, it produces error:
RuntimeError: CUDA out of memory. Tried to allocate 282.00 MiB (GPU 0; 31.75 GiB total capacity; 30.15 GiB already allocated; 90.00 MiB free; 30.37 GiB reserved in total by PyTorch)